
Повышение эффективности ОЦО с использованием цифровых технологий

Цифровизация давно стала одним из важнейших трендов как в бизнесе в целом, так и в индустрии ОЦО. «Северсталь-ЦЕС» относится к числу лидеров цифровизации, не случайно компания стала победителем в номинации «Лучший цифровой проект» конкурса «Лучший ОЦО 2025». Кира Лапина, генеральный директор «Северсталь-ЦЕС», рассказала Клубу ОЦО, какие элементы, внедренные в компании, позволяют сотрудникам правильно работать с ИИ-инструментами, каким образом ИИ встроен в разные уровни работы ЦЕС и что из опыта компании могут позаимствовать другие OЦО.
Теневой ИИ в ОЦО: почему им нужно управлять
Когда мы говорим об ИИ в ОЦО, первый вопрос для нас — не «какую модель выбрать», а «что уже происходит без нашего ведома». По данным исследования EY, 88% сотрудников используют ИИ – с разрешения компании или без него. Это и есть теневой ИИ: технология уже влияет на процессы, но компания не контролирует ни где это происходит, ни с какими данными, ни кто несет ответственность за результат.
Риск здесь не только в том, что данные могут утечь во внешний сервис. Куда серьезнее другое: результат работы модели может попасть в бизнес-процесс как готовое решение. Если сотрудник не понимает, где модель ошибается, и не проверяет ответ, то ошибка уходит дальше по цепочке.
Запрещать бессмысленно. Пока у людей нет безопасной альтернативы и понятных правил, они продолжают работать через личные аккаунты и личные устройства. Поэтому задача управленца – не закрыть доступ, а определить: что можно, в каких инструментах, с какими данными и кто отвечает за результат.
В Северсталь-ЦЕС мы для этого разграничили три уровня: публичные LLM – только для общедоступной информации; облачные API с DPA – для коммерческих данных без персональных; локальные модели on-prem – для защищенных данных при наличии контроля доступа.
Не запретить, а определить, как можно
Чтобы сотрудники работали с ИИ правильно, нужна не инструкция на 40 страниц, а понятная рамка из нескольких элементов. У нас их пять.
Матрица разрешенных сервисов – список того, что можно использовать, для каких задач и с какими данными. Публичный сервис – только для открытой информации, внутренняя LLM – для того, что нельзя выносить наружу.
Классификация данных – каждый сотрудник должен понимать, с чем он работает: публичная информация, внутренние данные, коммерческая тайна или персональные данные. Без этого матрица не работает.
Владельцы ИИ-кейсов – у каждого сценария должен быть конкретный человек, который понимает, как работает решение, несет ответственность за риск и знает, когда нужно остановить проект.
Обучение – политика работает только тогда, когда она переведена в конкретику: что можно, что нельзя, почему. Для этого нужны амбассадоры – люди внутри команд, которые помогают коллегам не нарушить правила там, где это не очевидно.
Технический контроль и журналирование – компания должна видеть, какие сервисы используются, какие данные передаются и где нужно вмешательство ИБ.
И базовый принцип, от которого мы не отступаем: ИИ помогает, но решение принимает человек. Результат модели без проверки сотрудником в работу не идет. Это защищает и компанию, и самого пользователя от последствий, которых никто не планировал.
Зрелость ИИ зависит не только от технологий
Мы работаем с моделью из пяти уровней зрелости ИИ: от базового – ручной труд, Excel, разрозненные данные, – до лидирующего, где работают автономные агенты, самокорректирующиеся прогнозы и встроенная этика ИИ (см. рисунок).
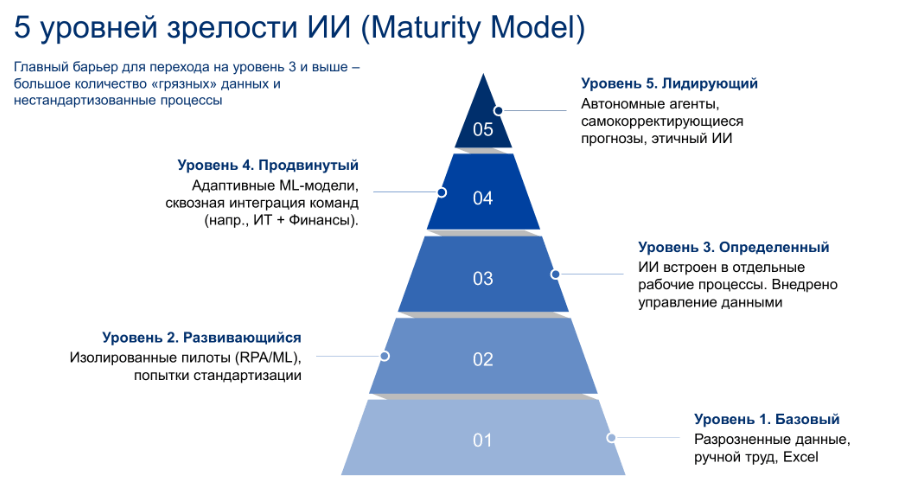
На практике большинство компаний застряли между вторым и третьим уровнем: пилоты RPA есть, попытки стандартизации – тоже, но ИИ пока не встроен системно в повседневную работу. Переход на следующий уровень тормозит не технология, а организационная база.
Типичные барьеры: «грязные» данные, нестандартизированные процессы, недоверие к вероятностным прогнозам, нехватка гибридных компетенций и сопротивление изменениям. Часть сотрудников по-прежнему делит мир на «я бухгалтер» и «это что-то айтишное», и это проблема. При внедрении ИИ бизнес-эксперт должен уметь поставить задачу, проверить результат, участвовать в разработке сценариев и отвечать за то, что получилось.
Тем, кто только начинает путь: стартуйте с руководителя/с себя. Когда руководитель сам понимает, что ИИ умеет, а что – нет, он может реально мотивировать команду и выбирать кейсы, которые сработают.
AI-native подход: три контура работы с ИИ
AI-native – это когда ИИ встроен не в один проект, а в разные уровни работы центра. У нас три контура.
DaVinchi и N8N – корпоративная ИИ-платформа внутри контура компании. Здесь можно работать с коммерческой тайной и персональными данными при соблюдении правил доступа. Через N8N сотрудники собирают агентов и сценарии, связывая ИИ с корпоративными системами, почтой, базой знаний Confluence и другими источниками.
RPA и ИИ-автоматизация – программные роботы, усиленные ИИ. Этот контур критически важен для промышленного эффекта: здесь уже есть правила документирования, хранения кода, мониторинга и поддержки решений. Не эксперимент – работающий конвейер.
Суперагентная система – координирует взаимодействие ИИ-компонентов для сквозных процессов. Нужна там, где одного ассистента или одного робота уже не хватает: задача требует цепочки действий и обращения к разным источникам данных.
Цифры уже значимые: 1500+ сотрудников подключены к платформе, создано 87 ИИ-ассистентов и 20 ИИ-агентов, используется более 150 макросов с ИИ. Восемь из десяти самых популярных ассистентов сделали сами сотрудники ЦЕС. Работают 12 роботов, экономический эффект от RPA в 2025 году превысил 45 млн рублей. Плюс два цифровых сотрудника: Юра – помощник по юридическим вопросам и E.V.A. — цифровой аналитик.
От гипотезы к эффекту: ИИ проходит ту же продуктовую воронку
Мы намеренно не выделяем ИИ в отдельную «особую» активность. Каждая инициатива проходит ту же продуктовую воронку, что и любой цифровой проект: идея — проверка гипотезы — оценка эффекта — MVP — пилот — промышленное внедрение — масштабирование.
Это принципиально важно. Интерес к ИИ легко превращается в хаотичное экспериментирование, где каждый делает что-то свое и никто не понимает, что работает. Чтобы этого не происходило, инициативы должны конкурировать за ресурсы по понятным критериям: ценность для пользователя, реализуемость, экономический эффект, риски, готовность данных, возможность масштабирования.
Один из инструментов поиска возможностей – Task Mining. Мы провели 3 пилота, выбрали подрядчика и за 5 месяцев развернули решение на 1500 человек. Итог: 215 гипотез для оптимизации, 154 проекта взяли в реализацию на первом этапе, 51 решение перевели в постоянный режим.
При этом Task Mining не заменяет прежнюю работу с процессами – он добавляет новый тип гипотез. Видно то, что раньше было невидимым: ручные действия, обходные маршруты, локальные файлы, повторные проверки, сверки и уточнения. Именно в этих местах ИИ и автоматизация чаще всего дают быстрый результат.
Люди остаются главным условием масштабирования
Масштабировать ИИ без людей не получится – это мы знаем точно. В Северсталь-ЦЕС обучение цифровым навыкам обязательно для всех. Внутри работает «Цифровая сталь» – пространство для развития практических компетенций.
По генеративному ИИ сотрудники проходят курсы «ГенИИ», обучающие курсы разного уровня. В Confluence (база знаний) – статьи, исследования, видеоуроки, инструкции, гайды и библиотека промтов. В корпоративном мессенджере – чат-бот с доступом к ассистентам DaVinchi, а в сети – корпоративные инструменты генеративного ИИ (цифровая платформа) и конструктор ботов.
Отдельная ставка у нас на амбассадоров и citizen developers. Это не ИТ-специалисты, но люди, которые умеют собрать макрос, написать простого агента, настроить сценарий. Они позволяют не ждать, пока идея попадет в ИТ-бэклог, и быстрее проверять гипотезы внутри бизнес-команд.
Мотивация здесь не только в интересе к инструменту. Для сотрудника владение ИИ – это профессиональная устойчивость. Чем больше рутины берет на себя технология, тем дороже стоит специалист, который умеет поставить задачу, проверить результат и управлять цифровым инструментом.
Вот как это работает в конкретных процессах.
Кейс 1. ИИ-агент для распознавания документов
ОЦО – это и много нестандартных документов: рукописных, плохо отсканированных, неформализованных. Классическое OCR справляется не всегда, а верификаторы тратили на такие документы значительное время.
Мы построили решение на ИИ-агенте для распознавания нестандартных документов, LLM-модели, системе классификации и экспорте данных в SAP. Агентская часть разработана внутри компании. Ключевой прием –последовательное использование нескольких нейросетей: одна модель уточняет результат другой, что заметно поднимает качество распознавания.
Кейс 2. Цифровой аналитик E.V.A.
E.V.A. – LLM-ассистент, интегрированный с календарем, кадровой системой, базой знаний и документами компании. Помогает сотрудникам быстро находить информацию, готовить материалы и работать с накопленными знаниями.
Для ОЦО это особенно ценно там, где люди тратят много времени не на основную задачу, а на поиск и сверку контекста. Чем больше база знаний, тем выше отдача. Нагрузка на экспертов снижается, скорость работы растет.
Кейс 3. Цифровой рекрутмент-бот
Бот на базе LLM проводит первичные интервью, анализирует ответы кандидатов – в текстовом и голосовом формате, автоматически ранжирует их по шкале от 0 до 5 и передает данные в рекрутинговую систему.
Особенно помогает в периоды активного найма, когда рекрутер работает с большим потоком. ИИ не принимает финальное решение, он структурирует данные, сравнивает ответы и выделяет тех, с кем стоит поговорить живому человеку.
Кейс 4. Автоматизация сверки взаиморасчетов
Сверка взаиморасчетов – типичный ОЦО-процесс с большим объемом повторяющихся операций. Мы используем OCR-инструмент Content Capture, RPA для сравнения распознанного документа с данными системы учета и автоматическое создание протокола разногласий при расхождении.
Проект начинали с крупных системных участков, затем расширили на локальные системы и внешних клиентов. Логика простая: сначала снять эффект там, где объем максимальный, а потом заходить в менее стандартизированные зоны – там он тоже есть.
Что из этого опыта можно взять другим ОЦО
Внедрение ИИ начинается не с выбора модели. Сначала – правила безопасного использования, классификация данных, подключение ИБ и юристов, обучение людей и продуктовая воронка для инициатив. Без этого фундамента любой пилот либо не масштабируется, либо создает риски, которых никто не ожидал.
Не ищите эффект только в очевидных массовых процессах. Ручные документы, Excel-выгрузки, сверки, уточнения, неформализованные входы – именно там ИИ закрывает задачи, которые классическими инструментами было автоматизировать сложно или невозможно.
ИИ должен жить в ответственности бизнеса, а не ИТ. Если процесс принадлежит финансам, HR или закупкам, то бизнес-владелец должен понимать, как работает сценарий, какой риск он несет и как проверяется результат.
Информационная безопасность – не последний барьер, а первый соучастник. Ее задача не только запрещать рискованные действия, но и помогать строить безопасный вариант: как можно, в каком контуре, с какими данными и при каком контроле.
И главное – без людей ничего не масштабируется. Амбассадоры, citizen developers, обучение руководителей, живая база знаний, – именно они превращают ИИ из эксперимента отдельных энтузиастов в рабочий инструмент всего центра.
ИИ дает эффект не там, где компания просто подключила модель. А там, где встроила технологию в процессы, правила, обучение и ответственность конкретных людей. Для ОЦО это и есть ключевой принцип: автоматизировать рутину, но сохранять управляемость решений.

Основные тренды развития аутсорсинга в 2026 году
Исследование компании Б1 - как изменился российский рынок аутсорсинга и требования к нему со стороны клиентов

Профиль современного ОЦО 2025-2026: итоги исследования
Как изменился функционал ОЦО, подходы к мотивации сотрудников, цели работы ОЦО и применяемые цифровые инструменты, – ответы в новом исследовании Клуба ОЦО.



